AWS Lambda Tutorial - how to create a daily scheduled task
In this tutorial, I’m going to talk about how to create a AWS Lambda function triggered by scheduled events.
For example, I want to schedule a daily job of pulling data from an API and save the data to a s3 bucket. First I need to create a lambda function, and choose “CloudWatch Events” from the trigger list.
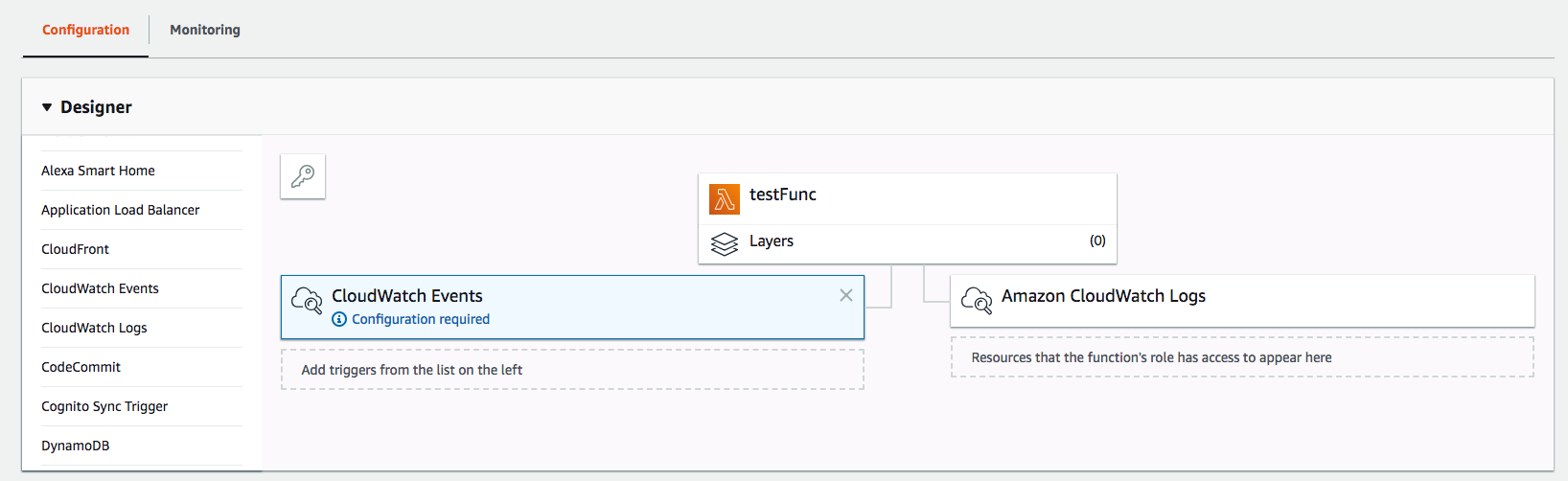
Then click on the center function itself and scroll down to see the file editor. You can choose to upload a zip file that contains your code, but for simple functions you can also just edit the code inline.
Choose whatever runtime you want. In my case, I’m using Python 3.7.
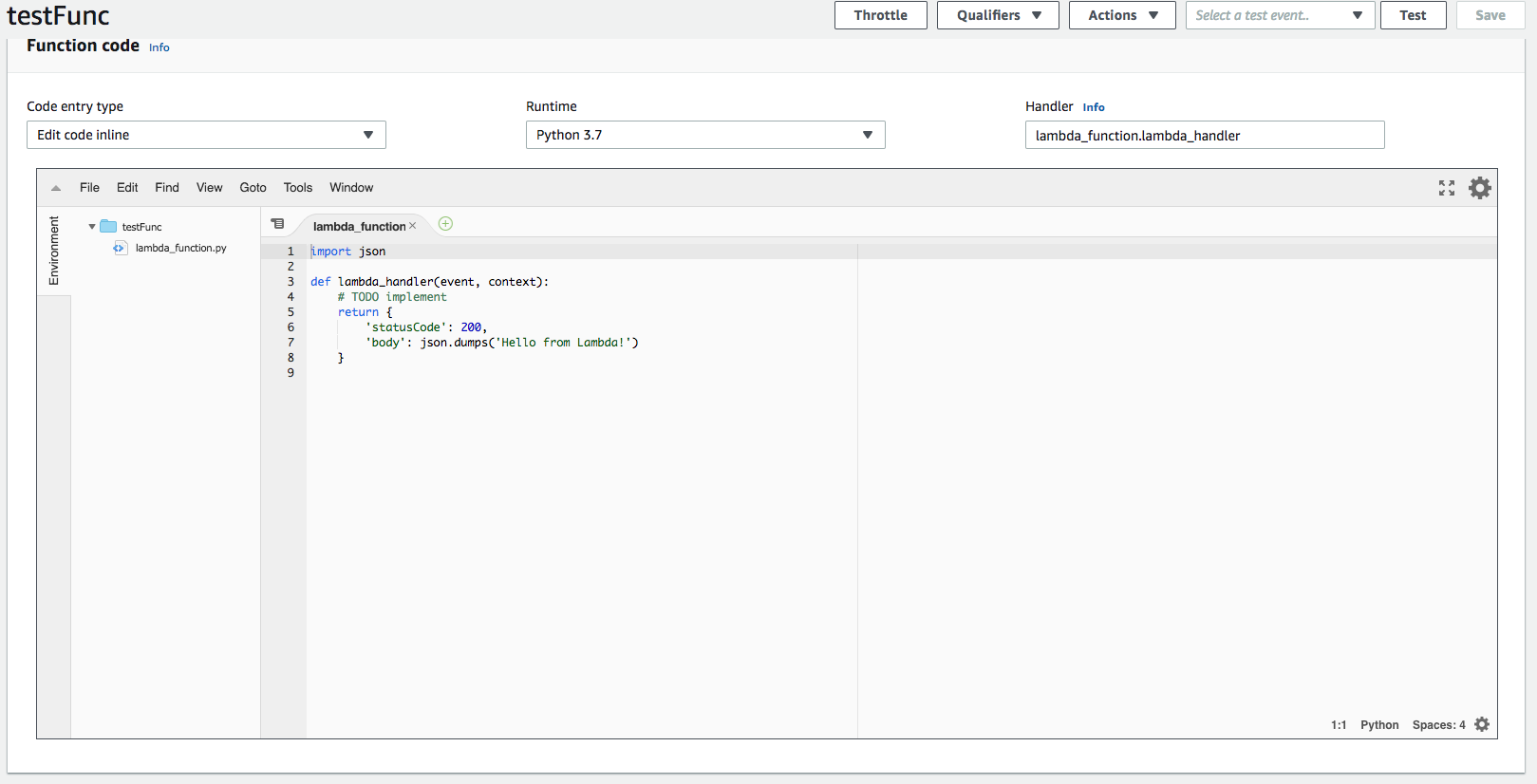
You can change the name of the function from lambda_handler to whatever you like, but make sure to change the name shown in “Handler” too.
You can start writing your function too as you like. For example, I have the following code to download a gz file from url and decompress, and finally save to s3 bucket.
1 | from io import BytesIO |
Just a few things to note here:
If you want to use
requests, you can usefrom botocore.vendored import requestsinsteadAWS Lambda does not support opening and saving files since it doesn’t have a filesystem. Therefore if you are doing some fileobject manipulation like me, you can use
BytesIOorStringIOinstead.If you are using other AWS resources, for example s3 like me in the example, you don’t have to authenticate in your code since they are both AWS resources. However you do need to make sure the IAM role you’re using for this Lambda function has sufficient permission to do whatever you need. For example in my case I had to make a bucket policy to grant write permission to this particular IAM role.
The bucket policy would look like something like this:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowS3Access",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<your-iam-role>"
},
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::<bucket-name>",
"arn:aws:s3:::<bucket-name>/*"
]
}
]
}